
<데이터 품질의 비밀> 속 ‘이것부터 확인하세요’

*출처: <WHAT IS DATA PIPELINE? EXPLAINED BY OUR DEVS>, 유튜브 채널 ‘TECH IN 5 MINUTES’
데이터는 흐릅니다. 다시 말해 그 흐름 중 어느 한 곳이라도 품질이 제대로 관리되지 않으면 다운스트림에서 문제가 생길 수 있다는 이야기입니다. 그러면 중요한 의사 결정을 위한 데이터 분석은 무용지물이 되고 맙니다. 그래서 요즘에는 ‘데이터가 없는 것보다 잘못된 데이터에 기반한 의사 결정이 더 무섭다’는 말도 자주 보입니다.
또 ‘데이터 다운타임’이라는 단어를 요즘 많이 들어보셨을 것입니다. 이는 데이터가 수집되지 않아 누락되거나 부정확하게 측정되는 것과 같이 데이터 손실로 인해 가동이 중지되는 상황을 의미합니다. 회사의 규모가 크거나 작거나, 데이터를 자주 다루는 회사이거나 아니거나 어디서든 일어날 수 있는 문제입니다.
기업용 데이터 베이스 업체인 줌인포(Zoominfo)에 따르면 2019년에만 약 20%의 기업이 데이터 품질 문제로 인해 고객을 잃는 경험을 했다고 합니다. 또 데이터 조직이 데이터 품질 문제를 처리하기 위해 전체 업무 시간의 40% 이상을 소모한다는 조사 결과도 있습니다.

*출처: <What is Data Observability?>, 유튜브 채널 ‘Monte Carlo’
하지만 저품질 데이터, 불량 데이터의 발생을 완전히 틀어막기는 거의 불가능합니다. 그러면 우리가 할 수 있는 일은 한 가지, 문제가 발생했을 때 적절하게 대처하는 것입니다. 그리고 그 대처의 첫걸음은 ‘무엇을 체크하면 되는지 인식’하는 일입니다.
그래서 <데이터 품질의 비밀: 데이터 신뢰를 쌓는 데이터옵스의 핵심과 엔드 투 엔드 단계별 가이드>에서는 데이터 파이프라인에 오류가 생겼거나 데이터를 신뢰할 수 없게 되는 상황을 맞았을 때 확인하면 좋을 3가지 체크리스트를 제안합니다.
그중 첫 번째 체크리스트는 데이터 문제의 심각성을 파악했고, 문제를 해결하기 위한 목적으로 원인을 찾았을 때 확인해보아야 할 7가지 항목입니다.
1. 데이터 품질 문제의 원인을 찾는 체크리스트
데이터 파이프라인은 데이터 변경, 코드 변경, 운영 환경 변경 이렇게 3가지 이유 때문에 가동이 중지되기 쉽습니다.
1) 기록된 데이터가 전부 잘못됐나요? 아니면 일부만 잘못됐나요?
2) 특정 기간의 데이터가 잘못됐나요?
3) 특정 하위 집합 또는 세그먼트의 데이터가 잘못됐나요?
4) 아직 설명하지 못하는 데이터의 새로운 세그먼트 또는 코드에 의존적인 세그먼트가 누락됐나요?
5) 최근에 스키마가 변경됐나요?
6) 숫자 단위가 변경됐나요? 예를 들어 화폐 단위라면 달러에서 센트로 변경됐나요? 시간의 단위라면 PST와 EST 중 어떤 기준을 쓰고 있나요?
7) 데이터를 변환하는 로직 변경이 있었나요? (ETL, SQL, Spark 작업 등) 테이블을 작업한 로직 또는 사건에 영향을 미친 특정 필드를 보면 무엇이 잘못됐는지 가설을 세우는 데 도움이 될 것입니다.
여기서 두 번째 체크리스트가 도출됩니다. 바로 앞서 보여드린 체크리스트 중 7번을 따로 떼어 더 확인해보아야 하기 때문입니다.
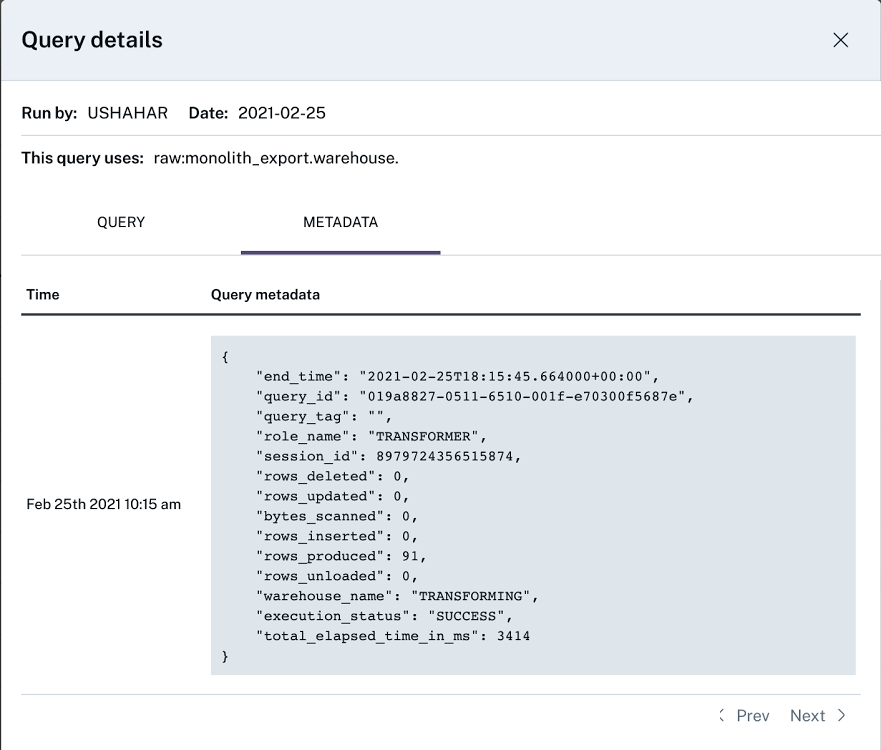
*출처: <데이터 품질의 비밀>, 한빛미디어, 2023
2. 로직 변경 관련 체크리스트
테이블을 생성한 로직에 영향을 미치는 특정 필드(또는 여러 필드)나 해당 테이블과 관련된 메타데이터를 들여다 보면 무엇이 잘못되었는지 그럴듯한 가설을 세울 수 있습니다.
이때 다음 체크리스트에 있는 4가지 질문을 스스로에게 던져보기를 권합니다.
1) 가장 최근에 테이블을 업데이트한 코드와 시기를 파악해보세요.
2) 관련 필드에는 어떤 계산이 들어갔나요? 해당 로직이 주어졌을 때 문제가 되는 데이터가 어떻게 나올 수 있었을까요?
3) 테이블을 임시로 쓴 적은 없나요?
4) 런타임 오류, 권한 문제, 인프라 오류 등과 같은 운영 문제도 데이터의 구조, 형식 및 버전 관리에 영향을 줄 수 있습니다.
3. ETL 로그 확인 시 활용할만한 체크리스트
앞서 언급한 데이터 문제, 데이터 다운타임은 ETL(Extract-transform-load, 추출-변환-적재) 작업을 실행하는 운영 환경의 직접적인 결과물입니다. ETL은 일반적으로 하나 이상의 데이터 저장소에서 데이터를 먼저 추출하고, 새로운 구조 또는 형식으로 변환한 다음, 최종적으로 대상 데이터 저장소에 적재하는 통합 단계입니다.
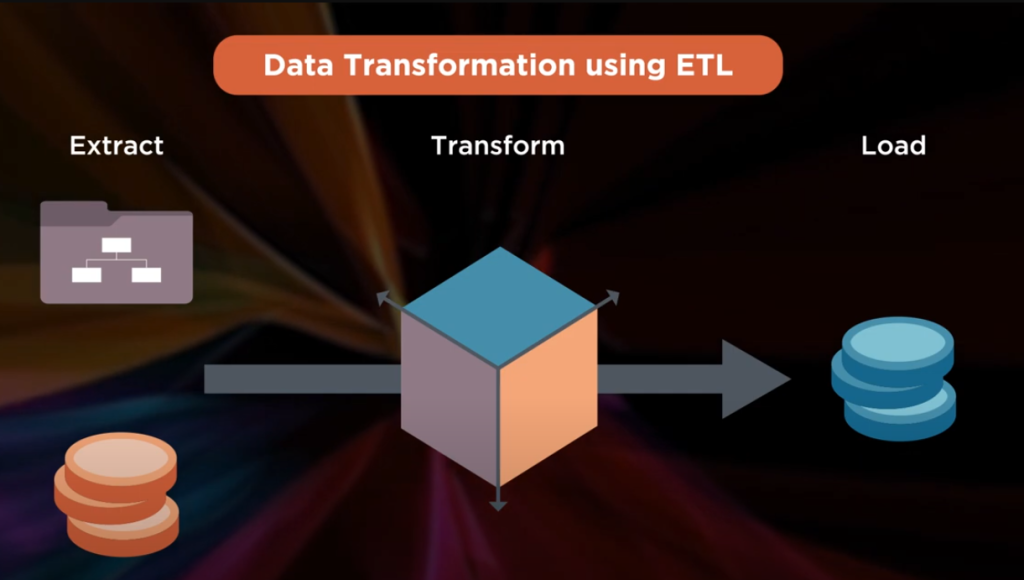
*출처: <WHAT IS DATA PIPELINE? EXPLAINED BY OUR DEVS>, 유튜브 채널 ‘TECH IN 5 MINUTES’
ETL 엔진의 로그를 살펴보고 오류를 추적하다 보면 데이터 문제를 해결할 실마리를 얻게 될 가능성이 높습니다. 따라서 데이터 문제와 관련된 모든 사람들이 ETL 작업이 수행되는 방법을 이해하고 관련 로그 및 스케줄링 설정 화면에 접근할 수 있어야 합니다.
이때 확인해야 할 5가지 항목은 다음과 같습니다.
1) 관련 작업에 오류가 있었나요?
2) 작업을 시작할 때 정상적이지 않은 레이턴시가 있었나요?
3) 쿼리가 오래됐거나 성능이 낮은 작업 때문에 레이턴시가 발생했나요?
4) 실행에 영향을 미치는 권한, 네트워킹, 인프라 문제가 있었나요? 최근 변경된 사항이 있나요?
5) 실수로 작업을 삭제했거나 종속 트리에 잘못 배치해서 작업 일정이 변경된 사례가 있었나요?
여기까지 보여드린 3가지 체크리스트는 데이터 파이프라인이 손상된 근본 원인을 분석하는 첫 단계에서 유용하게 사용할 수 있습니다. 지금 바로 우리 조직의 데이터 흐름을 살펴보고, 신뢰할 수 있는 데이터를 확보하기 위한 체크리스트를 확인해보시면 어떨까요?


